
NVIDIA GPUs H100 and A100 GPUs represent the cutting edge of AI acceleration. Initially designed for tasks like rendering images and videos, they have become indispensable for AI and ML due to their Tensor Cores that speed up matrix operations fundamental to neural networks.
Both the H100 and A100 offer impressive improvements over non-GPU computing methods. However, the H100 is a significant upgrade on the A100, and has several new features. This article compares their performance, cost, and architectures, helping you determine which GPU best meets the needs of your AI workload.
NVIDIA GPUs H100 vs. A100: Architectural differences
Overview
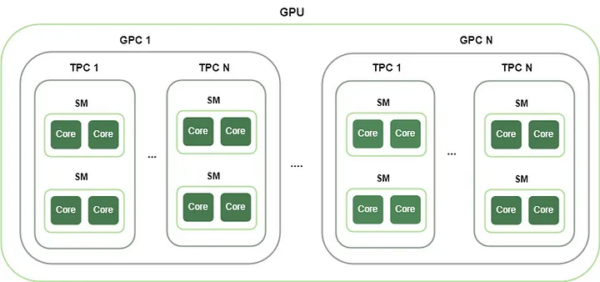
NVIDIA GPU architecture (overview)
Any NVIDIA GPU contains several Graphics Processing Clusters (GPCs). Each GPC has a raster engine and several Texture Processing Clusters(TPCs). Each TPC contains multiple Streaming Multiprocessors(SMs) where the actual data computing occurs. The SMs contain CUDA cores, Tensor cores, and other key components.
NVIDIA regularly releases new architectures (same basic design but technical specification differences). The A100 with NVIDIA Ampere architecture was launched in 2020, primarily focusing on ML workloads. In comparison, the H100, launched in 2022, was primarily designed for transformer-based neural networks. Its NVIDIA Hopper architecture was planned with large language models (LLMs) in mind.
Each Ampere GPU contains 7 GPCs, 28 TPCs, and 108 SMs. Every Hopper GPU contains 8 GPCs, 32 TPCs, and 80 SMs. These numbers reflect the design choices made by NVIDIA to optimize performance and efficiency in each architecture,
Next, look at more design differences between Ampere (A100) and Hopper(H100).
Tensor Cores
The Tensor Core is the main component in the SM that performs deep learning mathematical calculations. The A100 contains a third-generation Tensor Core that supports
- FP64 (64-bit floating point precision ) for high-performance scientific computing.
- TF32 (TensorFloat-32) for 32-bit range at slightly reduced precision to balance speed and accuracy.
- INT8/INT4 for inference acceleration, where precision can be traded off for speed.
Precision is the level of detail and accuracy used in numerical computations, particularly in representing floating-point (decimal) numbers. It determines how accurately a GPU can process and store numerical data during computations.
In contrast, Hopper brings fourth-generation Tensor Cores that handle the A100 mixed-precision matrix operations but also include advanced support for FP8 precision. This allows even faster training and inference performance without a significant accuracy loss in transformer models.
Structured sparsity
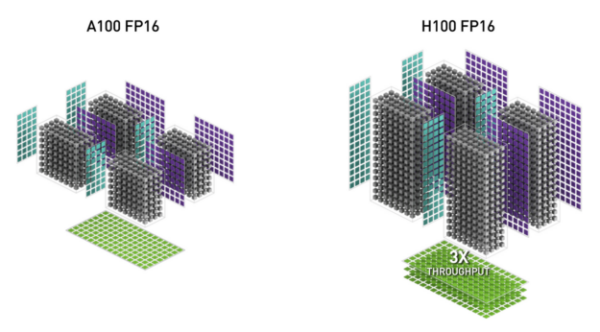
Both Tensor Cores support structured sparsity, a feature that removes certain weights in neural networks (e.g., redundant or zero weights). AI models only process the essential data components and experience a performance boost without reducing model accuracy.
However, the Hopper Tensor Core supports sparsity with enhanced efficiency. It delivers double the math throughput clock-for-clock, compared to A100. You can save 30% on operand delivery power for similar workloads.
H100 has a more efficient, 4th generation tensor core (Source)
CUDA Cores
Along with Tensor Core, both GPUs include CUDA cores for general-purpose parallel computing. CUDA gives direct access to the GPU’s virtual instruction set and memory for non-AI workloads like graphics rendering, physics simulations, gaming, and 3D modeling.
A100 CUDA cores deliver up to 2.5x the performance of the previous Volta architecture, especially in single-precision FP32 tasks. However, H100 CUDA cores give higher throughput in both FP32 and FP64 operations.
Thread block cluster
A100 CUDA programming organizes GPU tasks into a hierarchy of threads, thread blocks, and grids. Each thread block runs on a single SM, and thread blocks within the grid run independently. The H100 introduces a new thread block cluster feature. It allows developers to group multiple thread blocks together into a cluster, which can span across multiple SMs.
Different thread blocks running on different SMs synchronize more easily. Developers can also programmatically control clusters for increased efficiency in HPC tasks.
Dynamic Programming Accelerators
H100 CUDA cores also introduce Dynamic Programming Accelerators(DPX) capability. DPX accelerates algorithms that solve complex problems by breaking them down into simpler subproblems, solving each once and storing their solutions. The DPX instructions in the H100 can accelerate these algorithms by up to 7x compared to the A100.
Multi-Instance GPU technology
Multi-Instance GPU (MIG) technology allows the A100 GPU to be partitioned into multiple isolated instances. Each instance has its resources like memory, cache, and compute cores. This lets you allocate your GPU hardware to different users or workloads and increase overall hardware utilization.
H100 has a second-generation MIG that provides 3X more compute and 2X more memory capacity per GPU instance. It also includes Confidential Computing capability with TEE to secure workloads at the MIG level.
Memory architecture and bandwidth
The A100 features a High-Bandwidth Memory (HBM2e) that delivers up to 80 GB of memory and a 1.6 TB/s bandwidth. In contrast, the H100 upgrades to HBM3 memory, offering 80 GB capacity and 3.35 TB/s bandwidth. You get ultra-fast data transfer between the memory and the GPU for processing large HPC datasets.
In traditional GPU designs, including A100, data communication between SMs typically requires going through the global memory. In contrast, H100 introduces the Distributed Shared Memory feature. SMs can communicate directly with each other without needing to transfer data through global memory. It reduces bottlenecks and data access times and enables faster synchronization between SMs.
NVIDIA NVLink and NVSwitch
In practice, AI and HPC workloads run across multiple GPUs that work together to compute data. Ampere supports NVLink and NVSwitch technology, allowing multiple GPUs to be interconnected at high speeds. NVLink in Ampere delivers twice the throughput of the previous generation, enabling data transfer speeds of up to 600 GB/s between GPUs.
Hopper GPUs feature the next generation of NVLink technology, with NVLink 4.0, allowing 900 GB/s bandwidth. It minimizes communication bottlenecks between GPUs.
NVIDIA GPUs H100 vs. A100: Performance differences
What is the performance impact of all the hardware changes? Isolated tests conducted by NVIDIA show a significant performance boost on H100—up to 4X higher GPT3 training performance and 30X times higher inference performance compared to A100. Performances for non-AI workloads also show an increase of 7X thanks to the DPX technology.

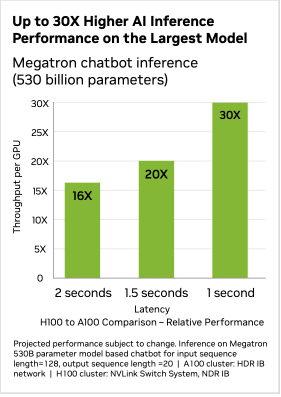
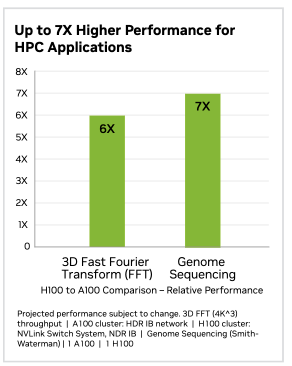
H100 vs A100 performance benchmarks(NVIDIA)
While the results may be accurate for NVIDIA testing, they don’t necessarily translate across the board for every workload. For example, independent benchmarking by CoreWeave shows a 2-3X increase in training speed.
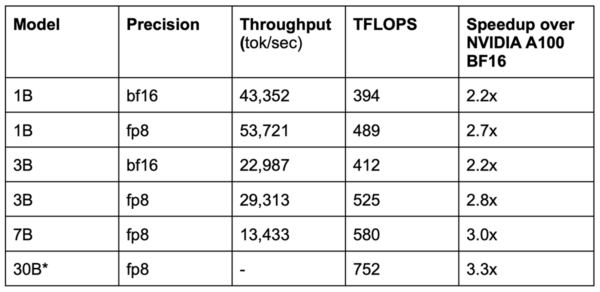
On average, you can expect a performance improvement of 2-5X times with the H100 for training and 10-20X times for inference.
NVIDIA GPUs H100 vs. A100: Cost differences
The H100 costs significantly more than the A100. But does it really? Let’s dive in. (All costs given below are in USD)
Cloud costs
If you are running your workloads in the cloud, you may have to pay anywhere from $2-$3/GPU/hour for the H100, depending on the provider. In contrast, the A100 costs $1-$1.5/GPU/hour.
Let’s perform calculations assuming an average price of $2.5 and $1.25 per GPU.
|
GPU |
Training resources |
Training time |
Cost per hour |
Total cost |
|
A100 |
4 GPUs |
10 hours |
1.25×4=$5 |
$50 |
|
H100 |
4 GPUs |
4 hours (assuming 2.5X performance) |
2.5X4=$10 |
$40 |
As you can see, the cost is lower for H100, even with conservative estimates. The more you optimize for H100 for better performance and scale, the more you realize cost savings.
Datacenter costs
Datacenter GPUs have their own role and purpose. Upfront costs of an 80GB A100 GPU vary from $15000-$20000. The upfront cost of an 80GB H100 varies from $35,000-$40,000. While purchasing hardware, investing in the latest technology is always better as older technology becomes obsolete quickly.
Also, it is essential to note that the power consumption of H100 is 30% less than A100, thanks to its Tensor Core design. You will see your power bills drop by 30% within the first month of making the switch!
Organizations reserving GPU cloud instances 24X7 are always better off purchasing the hardware. You could pay more than the hardware cost in just a single year of operations.
We take care of GPU colocation for you. We specialize in high-density racks and can take care of management and setup for you to deploy remotely. We can provide air-cooled, immersion, or direct-to-chip cooling with multiple power options and 15+ carriers on site.
What does the H100 have that the A100 doesn’t?
The H100 has many features that the A100 does not have or has an older version. We present the summary in the table below.
|
Feature |
A100 |
H100 |
|
Fourth-generation Tensor Cores |
Third-generation Tensor Cores |
6x faster chip-to-chip, 2x MMA rates, 4x performance using FP8 |
|
FP64 and FP32 Processing Rates |
3x slower compared to H100 |
3x faster IEEE FP64 and FP32 rates chip-to-chip |
|
HBM3 Memory Subsystem |
HBM2e, with 1.6 TB/s bandwidth |
HBM3 memory with nearly 2x bandwidth increase to 3 TB/s |
|
L2 Cache |
Smaller cache |
50 MB L2 cache, caches large portions of models and datasets |
|
Second-Generation MIG Technology |
First-generation MIG |
3x more compute capacity, nearly 2x more memory bandwidth per instance |
|
Fourth-generation NVLink |
NVLink with 600 GB/sec bandwidth. |
50% bandwidth increase, 900 GB/sec total bandwidth. |
|
Third-generation NVSwitch |
Older NVSwitch technology |
New NVSwitch technology, with 13.6 Tbits/sec switch throughput, hardware acceleration for collective ops |
|
PCIe Gen 5, 128 GB/sec |
PCIe Gen 4, 64 GB/sec total bandwidth |
Doubles the bandwidth, allowing faster data transfer rates between GPU components, |
|
DPX Instructions |
Not available |
Accelerates dynamic programming algorithms (non-AI) by up to 7x. |
|
Thread Block Cluster Feature |
Not available |
Adds control over thread blocks across multiple SMs, improving synchronization |
|
Distributed Shared Memory |
Not available |
Allows direct SM-to-SM communications |
|
Asynchronous Execution Features |
Not available |
Includes Tensor Memory Accelerator (TMA) for faster data transfers between memory and SM. |
|
Transformer Engine |
Not available |
Optimizes AI performance using FP8 and 16-bit, providing up to 9x faster training and 30x inference speed |
|
Confidential Computing support |
Not available |
First native Confidential Computing GPU, with MIG-level TEE and PCIe line rate protection. |
|
NVLink Switch System and Second-level NVLink Switches |
Not available |
Enables up to 32 nodes or 256 GPUs to connect with 57.6 TB/sec all-to-all bandwidth |
NVIDIA A100 H100 comparison – how to choose?
Choosing between the NVIDIA A100 and H100 depends on your workload needs. Since H100 is optimized for transformer models, it is a must-have for LLM workloads. Whether training your LLM or fine-tuning an existing one, you will get better cost-performance benefits in the long run with H100.
For non-AI workloads, if you have HPC workloads for scientific and medical research or other similar use cases, again, you should go with the H100. It offers much better performance and will help you achieve your research goals faster.
However, for smaller workloads like machine learning analytics, OCR, NLP, or fraud detection with fewer users, the A100 is more cost-effective. It provides sufficient performance without the higher investment of the H100. If your workload doesn’t justify the scale and upfront cost of the H100, the A100 is a great choice.
Conclusion
For decades, NVIDIA GPUs have reliably met performance requirements for data science, gaming, and other computing-intensive projects. NVIDIA is constantly innovating its hardware architecture to keep up with changing technologies. Organizations moving to LLM/AI adoption will benefit significantly from the architectural upgrades in H100. Cut down your power consumption and increase GPU usage for various use cases with the H100.
FAQs
How much better is H100 vs A100?
The NVIDIA H100 offers significantly improved performance over the A100, with up to 3x faster AI training and 30x faster AI inference for large language models. It features fourth-generation Tensor Cores, enhanced memory bandwidth, and additional architectural improvements, making it substantially more powerful for AI and HPC workloads.
What is the difference between H100 80GB and A100 40GB?
The H100 80GB has double the memory of the A100 40GB and uses faster HBM3 memory, providing nearly 2x the bandwidth(3 TB/s vs. 1.6 TB/s). The H100 also features fourth-generation Tensor Cores and FP8 precision, enabling faster performance for AI workloads than the A100.
How much faster is H100?
The H100 delivers up to 9x faster AI training and 30x faster AI inference on large language models compared to the A100, thanks to its advanced features like the transformer engine, improved Tensor Cores, and enhanced memory bandwidth. This makes it a superior choice for demanding AI applications.
Looking for GPU colocation?
Deploy reliable, high-density racks quickly & remotely in our data center
Want to buy or lease GPUs?
Our partners have H200s and L40s in stock, ready for you to use today






