
The NVIDIA H200 GPUs, released in mid-2024, are widely available in most countries. While some supply constraints remain, you can still get your hands on these GPU servers within a few months.
But is it worth investing in the H200? Should you choose between cloud-based or on-prem solutions? How can you best store and manage your NVIDIA H200 GPU servers?
This article explores NVIDIA H200 features, applications, and benefits. We also compare it with similar products and discuss pricing, power consumption, and other practical considerations.
What is NVIDIA H200?
The NVIDIA H200 is the latest NVIDIA GPU based on cutting-edge Hopper architecture. It offers enhanced memory and performance capabilities compared to the previous H100 GPUs. Improved speed and more energy optimization features mean your AI and HPC workloads cost much less run to run. Depending on your AI usage, switching to the H200 can cut costs by as much as 50%!
The NVIDIA H200 is available as NVL (NVIDIA Virtual Link) and SXM (Secure eXpress Module). NVL is a PCIe-based GPU designed for use in standard data center servers. It is compact and more energy-efficient. The SXM offers increased memory capacity, but its larger size and increased cooling requirements consume more power.
You can purchase the NVIDIA H200 GPUs to add to your current data center infrastructure or purchase ready-to-use data center servers and clusters from NVIDIA solution partners. You can also consider investing in the NVIDIA DGX™ platform—it combines H200 GPUs with the best NVIDIA software and infrastructure in a modern, unified AI development solution.
NVIDIA H200 features
NVIDIA H200 is based on Hopper architecture. It introduces five breakthrough features in GPU design compared to the previous Ampere architecture.
Transformer engine
The Transformer engine in the H200 leverages mixed-precision floating-point computations to optimize the performance of transformer-based models. It dynamically manages precision to maximize speed without sacrificing accuracy. The H200 is one of the best GPUs for AI, achieving substantial speedups in AI training and inference tasks, with up to 30x faster inference for large models than Ampere.
Fourth-generation Tensor Cores
Hopper’s fourth-generation Tensor Cores deliver up to 6x the performance of Ampere, thanks to enhancements like support for floating point precision and improved sparsity utilization—efficiently processing sparse data with more zero values. In the H200, these Tensor Cores boost matrix multiplication and AI workloads across multiple precisions. They make the GPU highly efficient for compute-heavy tasks in AI and HPC.
Confidential computing
The H200 incorporates NVIDIA’s secure Multi-Instance GPU (MIG) technology for confidential computing. You get secure isolation of workloads, and sensitive computations are protected during processing. You can be confident of data security even in multi-tenant environments.
NVLink Switch System
The H200 uses the NVLink Switch system to interconnect GPUs with a bandwidth of up to 900 GB/s, more than 7x that of the previous generation. You can scale AI and HPC workloads across multiple GPUs and efficiently train models with trillions of parameters.
Grace Hopper super chip integration
Through the NVLink-C2C interconnect, the H200 integrates with NVIDIA’s Grace CPU, forming the Grace Hopper super chip. This pairing provides a unified memory model and up to 7x faster CPU-GPU communication than traditional systems. It significantly improves throughput for large-scale applications like data analytics and AI model training.
What is the NVIDIA H200 used for?
The NVIDIA H200 is designed for advanced workloads in AI and high-performance computing (HPC).
Artificial intelligence
You can use it to train and infer large language models (LLMs) like GPT and BERT. The H200 gives 2X the speed even for models with 100 Billion+ parameters. You can use it to run all types of AI applications, from chatbots to fraud detection, automated content generation, real-time language translation, and more.
The H200 accelerates image recognition, object detection, and video analytics tasks in computer vision. It also supports image synthesis, video editing, and the creation of virtual environments for gaming or simulations. You can use it for applications in autonomous vehicles, augmented reality/virtual reality (AR/VR), healthcare, finance, manufacturing, security, and more.
High-performance computing.
The H200 can support all scientific research and large-scale simulations in climate modeling, genomics, physics, etc. Its high computational throughput is helpful for weather prediction, pharmaceutical research, and molecular dynamics. You can run all HPC workloads—from risk analysis and algorithmic trading to real-time data analytics. Its NVLink capabilities support multi-GPU scaling, making it a powerful choice for both centralized and distributed systems.
What is the difference between H100 and H200?—H200 Benefits over H100
H100 was the first Hopper architecture GPU released in 2022. H200 significantly improves the base architecture, doubling memory capacity and computation power. You get the following additional benefits by switching to the H200.
Larger and faster Memory
The NVIDIA H200 Tensor Core GPU is the first to feature 141 GB of HBM3e memory, with 4.8 terabytes per second (TB/s) bandwidth—nearly double the capacity and 1.4x the bandwidth of the H100. You can accelerate AI tasks and process massive datasets while reducing latency. The H200’s enhanced memory capabilities address bottlenecks, delivering faster time-to-results.
Higher inference performance
The H200 demonstrates up to 1.6x better inference performance and significantly higher throughputs than the H100 across various LLM configurations. Independent benchmarking shows that the H200 outpaces the H100 when running Llama2 13B with batch size (BS) 128 and Llama2 70B with BS 32. For GPT-3 175B, using eight H200 GPUs doubles the throughput compared to eight H100 GPUs. Businesses deploying LLMs at scale can deliver more to customers at much less cost.

HPC performance boost
Memory bandwidth is significant in HPC applications like molecular dynamics, climate modeling, and quantum mechanics simulations. The H200’s improved bandwidth allows faster data access and up to 110x faster time-to-results than CPU-only configurations. It reduces processing delays and supports complex datasets for research and industrial applications.
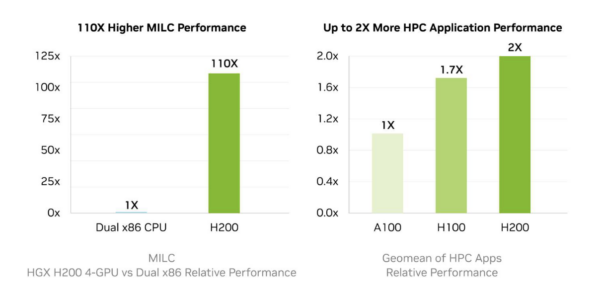
Energy efficiency and sustainability
Despite its increased performance, the H200 provides an improved power profile than the H100. It can reduce energy consumption and, consequently, TCO by 50%. You can operate more sustainably while achieving greater computational throughput. Lower operational expenses and advance eco-friendly AI solutions to improve the world without harming the planet.

What is the difference Between NVIDIA H200 and AMD MI300X?
Advanced Micro Devices (AMD) is an NVIDIA competitor that also manufactures GPUs. The AMD MI300X is a cutting-edge data center GPU with higher memory than the H200. However, the NVIDIA software eco-system, customized for the H200, makes investing in NVIDIA over AMD more worthwhile. NVIDIA’s CUDA framework offers developer tools and technology to enhance hardware performance in practice.
Architecture and memory
The NVIDIA H200 is built on the Hopper architecture with 141GB of HBM3e memory and a memory bandwidth of 4.8 TB/s. In contrast, the AMD MI300X utilizes CDNA 3.0 architecture, offering 192GB of HBM3 memory with a larger bandwidth of 5.3 TB/s.
Performance
Lab benchmarks show that MI300X leads in FP32 performance with 163.4 TFLOPS compared to the H200’s 67 TFLOPS. However, this may not be the case in practice because performance efficiency comes only when software and hardware work together.
Power consumption
The H200 has a lower TDP (700W vs. 750W) and reduced operational costs. The higher efficiency of NVIDIA’s software layer can further reduce power consumption.
How much power does the Nvidia H200 use?
The NVIDIA H200 Tensor Core GPU has a Thermal Design Power (TDP) of 700 watts for a single GPU under normal operating conditions. Power requirements scale accordingly for systems with multiple GPUs, such as the HGX H200 setups. A 4-GPU configuration requires 2.8 kW, while an 8-GPU setup demands 5.6 kW. This level of power consumption is typical for data centers handling advanced AI and HPC workloads.
The H200 power consumption is comparable to H100 but with performance improvements in memory bandwidth and inference capabilities. The H200 achieves better performance per watt, reducing overall energy consumption for the same workloads. Its energy efficiency improvements help data centers manage operational costs and meet sustainability goals.
How much is a H200 chip?
An NVIDIA H200 NVL Graphic card is priced at $30,000. However, for practical purposes, you must purchase a server with 6-8 GPUs. Servers can range from $275,000 to $500,000 depending on GPU configurations, server hardware manufacturer, and other configurations. It is best to approach an NVIDIA Solutions partner—they can analyze your workloads and future requirements and suggest the best server configurations for you.
Once you have your hardware, you need to store it with adequate cooling and security arrangements. A GPU colocation service is the most cost-effective and practical solution. A third party manages the data center infrastructure and maintains your H200 GPU hardware for you.
For example, our Houston Data Center is strategically located with cutting-edge capabilities, such as infinite fuel sources, indoor generators, and waterless cooling, to provide the highest reliability, convenience, and uptime for customers. We are the only data center in Houston outside the 500-year floodplain that is still built 3 feet above ground level. With a single-sloped roof and two layers of leak protection, including a concrete deck, it also provides hurricane resistance to keep your AI hardware safe in every situation.
Should I purchase NVIDIA H200 upfront or run my workloads in the cloud?
The early 2010s saw a massive increase in cloud adoption, and many organizations moved their workloads to the public cloud for flexibility and scale. However, the cloud created its own challenges.
- Cloud introduces latency as data has to be transferred to cloud servers that are often physically located far from the data users and sources.
- Securing cloud workloads is complex because of many endpoints and configurations. Even minor errors lead to massive data breaches.
- While the per-hour cost of cloud consumption is low, the cloud is designed to make users access a range of paid services for any one task. Costs can add up quickly, resulting in large monthly bills and unexpected operational expenses.
Hence, post 2022, the trend has shifted. Organizations are now moving away from the cloud and back to on-prem infrastructure.
Buying your own hardware gives you complete control over your AI workloads. You can run your AI models closer to your data sources and users. Our cloud vs. data center cost analysis shows you can save hundreds of thousands of dollars and recover initial investment in just two years.
Also, you don’t have to set up all data center infrastructure from scratch. AI colocation services like TRG make it very convenient to run self-managed AI workloads. You only purchase the hardware; we handle installation, maintenance, troubleshooting, physical security, cooling, etc., and provide high reliability and uptime guarantees.
Conclusion
The NVIDIA H200 is setting new standards in GPU innovation, making it a game-changer for organizations handling large-scale AI and HPC workloads. By enabling faster time-to-results and scalable AI deployment, the H200 empowers enterprises to not only meet but exceed their computational goals. Organizations looking to cut down operational costs and build sustainable AI solutions should consider investing in H200 for maximum benefits.
FAQs
How many cores are in the NVIDIA H200?
The NVIDIA H200 GPU contains 16,896 CUDA cores for handling parallel computations efficiently. It also has 528 fourth-generation Tensor Cores that support 8-bit, 16-bit, 32-bit, and 64-bit floating point operations.
Any NVIDIA GPU contains several Graphics Processing Clusters (GPCs). Each GPC has a raster engine and several Texture Processing Clusters(TPCs). Each TPC contains multiple Streaming Multiprocessors(SMs) where the actual data computing occurs. The SMs contain CUDA cores, Tensor cores, and other key components.
Every H200 GPU contains 8 GPCs, 32 TPCs, and 80 SMs. Each SM includes about 200 CUDA cores and 6 Tensor cores.
How much memory does the NVIDIA H200 have?
The NVIDIA H200 is equipped with 141 GB of HBM3e memory, offering nearly double the capacity of its predecessor, the H100. It also has a memory bandwidth of 4.8 TB/s, providing the speed and capacity necessary for large-scale AI models and memory-intensive HPC workloads.
What is the benchmark for H200 GPU?
The NVIDIA H200 GPU excels in AI and HPC benchmarks. It demonstrates up to 1.6x higher inference performance for models like Llama2 70B compared to the H100, with efficiency gains in tasks like generative AI and simulations. These benchmarks highlight its superior throughput, powered by its advanced memory bandwidth and computational capabilities.
How much faster is H200 than H100?
The larger memory capacity, faster bandwidth, and energy-efficient architecture of H200 make it much faster than H100. In the H200 vs. H100 battle, The NVIDIA H200 delivers up to 2x higher inference speeds for models like Llama2 and 1.6x better performance for larger models like GPT-3.
Looking for GPU colocation?
Deploy reliable, high-density racks quickly & remotely in our data center
Want to buy or lease GPUs?
Our partners have H200s and L40s in stock, ready for you to use today






