
The rapid evolution of artificial intelligence (AI) and machine learning (ML) has intensified the demand for high-performance computing solutions. Two prominent contenders in this arena are AMD’s Instinct MI300X and NVIDIA’s H100 GPUs. Both are engineered to accelerate AI workloads, but they differ in architecture, performance metrics, and efficiency. This article delves into these differences, supported by benchmark tests and graphical analyses.
Architectural Overview
AMD Instinct MI300X
The MI300X is AMD’s flagship AI GPU, built on the CDNA 3 architecture. It features a substantial 192 GB of HBM3 memory, delivering up to 5.3 TB/s of memory bandwidth. The GPU boasts a peak performance of 1.31 petaflops at FP16 precision, positioning it as a formidable competitor in the AI landscape.
NVIDIA H100
NVIDIA’s H100 GPU is based on the Hopper architecture and comes with 80 GB of HBM2e memory, offering up to 3.35 TB/s of memory bandwidth. It achieves a peak performance of 989.5 teraflops at FP16 precision. NVIDIA has also introduced the H200, which narrows the gap with increased memory capacity and bandwidth.
Performance Benchmarks
Compute Throughput
In low-level benchmarks, the MI300X demonstrates superior instruction throughput compared to the H100. Tests reveal that the MI300X can be up to five times faster in certain operations, with a minimum advantage of approximately 40%.
Memory Bandwidth and Latency
The MI300X outperforms the H100 in memory bandwidth, offering 60% more bandwidth and more than double the memory capacity. However, the H100 exhibits 57% lower memory latency, which can influence performance depending on the workload.
AI Inference Performance
In AI inference tasks, particularly with large language models like LLaMA2-70B, the MI300X shows a 40% latency advantage over the H100. This advantage is attributed to its higher memory bandwidth and capacity, enabling more efficient handling of large models.
Benchmark Testing Graphics
To provide a visual representation of the performance differences, let’s examine some benchmark graphs:
Compute Throughput Comparison
This graph illustrates the instruction throughput advantage of the MI300X over the H100 across various operations, highlighting up to a 5x performance increase in certain tasks. Source: Next Platform
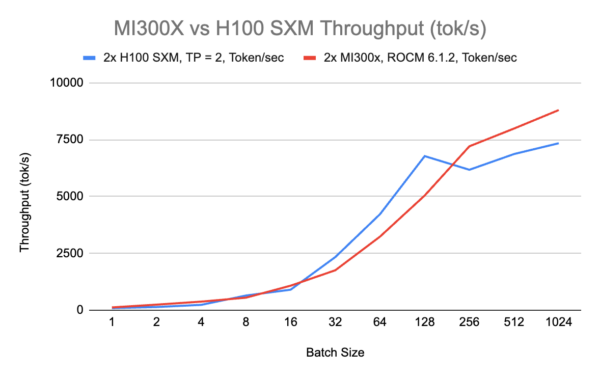
Memory Bandwidth and Latency
A comparative analysis of memory bandwidth and latency, showcasing the MI300X’s superior bandwidth and the H100’s lower latency. Source: Tom’s Hardware

AI Inference Performance
This graph compares the latency in AI inference tasks between the two GPUs, emphasizing the MI300X’s 40% latency advantage in handling large language models. Source: SemiAnalysis

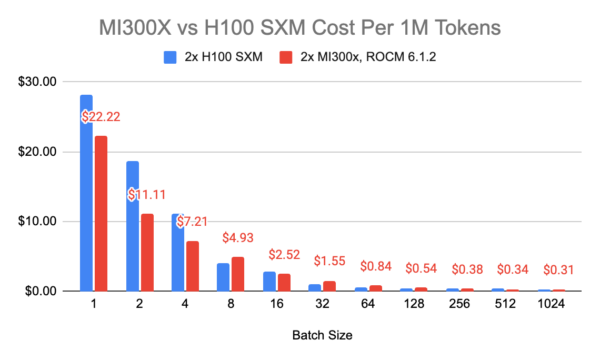
Cost Efficiency per 1M Tokens
An analysis of the cost per million tokens processed, indicating the scenarios where each GPU offers better cost efficiency. Source: RunPod
Serving Benchmark: Latency and Throughput
A comprehensive comparison of latency and throughput in real-world serving scenarios, demonstrating the performance consistency of both GPUs under varying loads. Source: ServeTheHome
Cost Efficiency
Cost efficiency is a critical factor in selecting a GPU for AI workloads. Pricing varies across cloud providers; for instance, on RunPod’s Secure Cloud, the H100 SXM is priced at $4.69 per hour, while the MI300X is at $4.89 per hour. At smaller batch sizes (1 to 4), the MI300X is more cost-effective, with costs ranging from $22.22 to $11.11 per 1 million tokens, compared to the H100 SXM’s $28.11 to $14.06. At higher batch sizes (256, 512, and 1024), the MI300X regains its cost advantage, offering lower costs per 1 million tokens compared to the H100 SXM.
Software Ecosystem and Compatibility
NVIDIA’s CUDA platform has long been the industry standard for AI and ML development, offering a mature and comprehensive ecosystem. AMD’s ROCm platform is gaining traction but still lags in terms of software support and community adoption. This disparity can influence the ease of development and optimization on these GPUs.
Conclusion
Both the AMD Instinct MI300X and NVIDIA H100 are formidable GPUs tailored for AI workloads, each with distinct strengths. The MI300X offers superior memory capacity and bandwidth, translating to advantages in specific scenarios, particularly at very low and very high batch sizes. Conversely, the H100 demonstrates robust performance at medium batch sizes and benefits from a more mature software ecosystem.
The choice between these GPUs should be guided by the specific requirements of your AI workloads, including model size, batch processing needs, and software compatibility. Future developments in software optimization and hardware iterations are likely to further influence the performance dynamics between these two competitors.
Looking for GPU colocation?
Deploy reliable, high-density racks quickly & remotely in our data center
Lease the most reliable GPUs
Our partners have B200s and L40s in stock, ready for you to lease today






