
Are you looking to purchase hardware infrastructure for AI workloads? Various options are available, so consider your organization’s specific needs. If you have the time and resources, you may invest in custom GPU boards and build your server racks. However, for a ready-to-use approach, turn-key solutions offer a combination of hardware and software designed to run any AI workload.
One such solution is the NVIDIA DGX, a supercomputer designed to meet enterprise AI demands. This article explores everything you need to know to determine if the DGX is the right fit for your organization’s AI infrastructure.
What is NVIDIA DGX?
An NVIDIA DGX system is a supercomputing platform that combines cutting-edge NVIDIA hardware and software with state-of-the-art AI GPUs for production-ready development.
With AI capabilities accelerating rapidly, teams are expected to deliver smarter chatbots, complex recommendation systems, and generative AI capabilities in every operational aspect. To maintain a competitive edge, organizations need a full-stack technology solution that can meet customer demands and drive innovation. NVIDIA DGX systems integrate into existing infrastructure and help organizations scale AI innovation at a rapid pace.
Launched specifically for enterprise AI in 2016, the NVIDIA DGX platform incorporates nearly a decade of NVIDIA’s AI expertise. Every component of the platform has been designed and improved based on the learnings from previous training runs and AI breakthroughs. This institutional knowledge, incorporated into the design, gives you direct access to the same software tools and computing infrastructure that delivers NVIDIA innovation.
With a DGX system, your developers can run everything from complex deep learning architectures to multimodal language models with billions of parameters— all while accessing a large library of optimized software that unlocks productivity.
What are the components of the NVIDIA DGX platform?
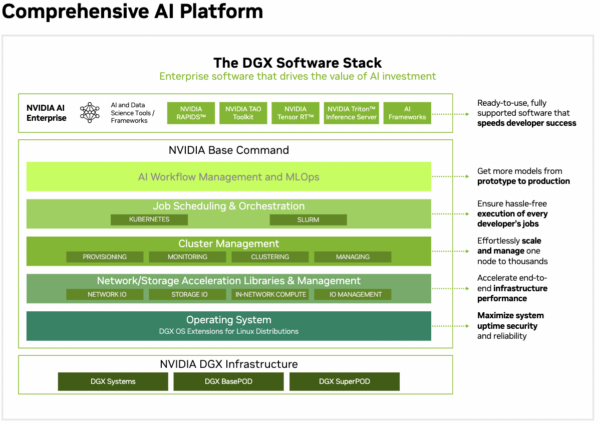
NVIDIA DGX Solution Components (Source)
As a full-stack solution, NVIDIA DGX includes several different components.
NVIDIA DGX Infrastructure
NVIDIA DGX infrastructure refers to the hardware components in the DGX platform. You can choose the configurations that best suit your needs and budget.
NVIDIA DGX B200/H200/A200
The NVIDIA DGX B200 is a physical server containing 8 Blackwell GPUs offering 1440GB RAM and 4TB system memory. It also includes 2 Intel CPUs and consumes 14.3kW power at max capacity. Large workloads typically require several DGX B200s working together. The Blackwell currently has a waitlist, so if you want immediate availability, you must choose between the NVIDIA DGX H200 and NVIDIA DGX A100 versions. While older versions, these data center GPUs still give competitive performance at a lower budget.
NVIDIA DGX BasePOD
DGX BasePOD combines several NVIDIA DGX B200s with storage technologies using InfiniBand and Ethernet. It provides ready configurations to link multiple DGX B200s so organizations can quickly scale out system design from one node to dozens that work together to perform complex deep learning tasks at optimum performance. It ensures the NVIDIA DGX platform does not suffer performance degradation or bottlenecks for AI workloads.
NVIDIA DGX SuperPOD
The DGX SuperPOD allows organizations to scale tens of thousands of NVIDIA B200 Superchips and effortlessly perform training and inference on trillion-parameter generative AI models. It includes liquid-cooled racks, each containing 36 NVIDIA Grace CPUs and 72 Blackwell GPUs integrated as one powerful processor with NVIDIA NVLink. Multiple racks connect with NVIDIA Quantum InfiniBand, so you can scale up to thousands as needed.
NVIDIA Base Command
NVIDIA Base Command is the operating system that powers the NVIDIA DGX platform. It also includes AI workflow management, cluster management, computing, storage, and network libraries, so you have everything you need to build and run any AI application on the system. You can visualize the Base Command as a set of infrastructure software layers, explained below.
Operating system
The DGX OS libraries communicate with the underlying hardware. They coordinate with all underlying GPUs, CPUs, memory, and peripheral storage so that the platform functions as a single machine.
Network/storage acceleration
This layer contains libraries that enhance the speed and efficiency of data transfers and storage access. Network IO ensures fast data movement across GPUs, while Storage IO streamlines access between GPU and memory storage. Additionally, In-Network computing allows some computations to occur directly within the network, significantly reducing latency. IO Management balances and optimizes input and output tasks across the system.
Job scheduling & orchestration
This layer manages the allocation of computational power for AI tasks. It integrates with popular orchestration tools, such as Kubernetes for containerized workloads and SLURM, a job scheduler widely used in high-performance computing environments. These tools enable AI teams to manage and scale machine learning tasks while optimally utilizing resources for various workloads.
Cluster management
This layer simplifies the administration of the multiple DGX systems that operate as a unified cluster in the platform. It provides tools for provisioning new hardware and monitoring performance and health metrics. Developers can manage the multiple DGX units and centrally control all computational resources.
AI workflow management and MLOps
The topmost layer within Base Command provides all the tooling needed for end-to-end AI model lifecycle management. It facilitates everything from experiment tracking to model deployment, so developers can quickly move AI models from prototype to production. You can improve models iteratively and build custom AI development pipelines at speed. Ultimately, you get unified AI management governed by enterprise service-level agreements (SLAs).
NVIDIA AI Enterprise
Imagine you purchased the latest Windows Desktop computer. You have the hardware and operating system, but you must install all the software applications to start your work. Similarly, DGX infrastructure and Base Command give you the supercomputer needed to build AI applications. But you can’t use it optimally without the right developer software.
NVIDIA AI Enterprise is a suite of enterprise-grade tools that enhance the DGX platform’s AI capabilities. For example, it includes:
- NVIDIA RAPIDS for accelerated data analytics and machine learning
- NVIDIA TAO Toolkit for streamlined model training
- NVIDIA TensorRT for optimizing AI models for inference.
NVIDIA Triton Inference Server ensures the scalable and efficient serving of AI models, while pre-integrated AI Frameworks like PyTorch and TensorFlow are optimized to work seamlessly with DGX systems. The software suite allows you to innovate rapidly for specific use cases.
Understanding NVIDIA DGX price
You can access NVIDIA DGX through the following payment models.
Public cloud
NVIDIA DGX Cloud lets you access the supercomputer through Amazon Web Service. Project Ceiba on AWS will offer NVIDIA Blackwell architecture-based DGX Cloud with 20,000+ GB200s early next year. At the time of writing, you can access EC2 servers with NVIDIA H200 GPUs at USD$84/ hour.
Colocation
The best way to access DGX today is to purchase the system upfront from NVIDIA and store it in an AI colocation space. Third-party data centers provide secure, high-performance environments with optimized cooling, power, and network connectivity while you retain full control over your hardware. This option is ideal for companies that want the flexibility of owning their DGX systems but need a reliable, secure location for their equipment.
DGX H200 systems are currently available for $400,000 – $500,000. BasePOD and SuperPOD systems must be purchased directly from NVIDIA. There is a current waitlist for B200 DGX systems. Contact NVIDIA to get on the list to receive priority delivery over 2025-2026.
Once purchased, you can house your DGX system at our Houston Data Center. It is the only data center in Houston with hurricane protection, regulatory compliance, and power supply capacity to meet the needs of DGX storage. Their managed colocation services will handle all your data center relocation and installation needs. You can have your custom GPU data center built and operational without leaving your primary office location!
Price comparison
The price comparison is for the DGX H200. Given that DGX H200 is accessible via AWS Ec2 P5 at $84/hour, for 24/7 operations you have:
|
Daily bill – DGX AWS Cloud |
Yearly bill – DGX AWS Cloud |
One-time purchase—DGX H200 |
|
$2016 (84X24) |
$735,840 |
$400,000 |
It is much more cost-efficient to purchase the DGX upfront and use GPU co-location services than to pay ongoing cloud expenses for DGX workloads. Also, it is important to note that AWS EC2 P5 is not fully managed DGX. It is only the infrastructure layer of the DGX system that is offered as a cloud service. All layers of the NVIDIA DGX platform will only be accessible in the cloud once Project Ceiba goes live.
FAQs
What does DGX stand for in Nvidia DGX?
DGX stands for “Deep GPU Xceleration” in NVIDIA DGX, symbolizing NVIDIA’s purpose-built platform for accelerating AI and deep learning workloads. It is an all-in-one solution with integrated hardware, software, and support for enterprise AI requirements.
What is the DGX H200?
The NVIDIA DGX H200 is an advanced AI supercomputing system featuring NVIDIA H200 GPUs. It is a group of servers and workstations that integrate and work together to run complex AI workloads at high performance and scale. It is suitable for enterprise and research applications.
What is the difference between DGX and HGX?
DGX systems are fully integrated AI supercomputers built for end-users, combining hardware and software for AI applications. HGX, on the other hand, refers to NVIDIA’s hardware platform its partners use to build custom AI and high-performance computing (HPC) systems. DGX is turnkey, while HGX is modular.
How powerful is a DGX GPU?
A DGX system integrates thousands of NVIDIA GPUs, each capable of delivering over one petaflop of AI performance. This immense computational power enables the DGX to handle cutting-edge workloads like training large-scale models, HPC simulations, and real-time AI inference.
Who manufactures DGX?
NVIDIA designs and manufactures DGX systems, leveraging its leadership in GPU technology and AI infrastructure. NVIDIA builds these systems in-house to ensure the highest integration, performance, and reliability standards for enterprise AI solutions.
Is the NVIDIA DGX a server?
No. The NVIDIA DGX is not a single machine but a collection of many servers with integrated storage, networking, and other AI infrastructure. It also includes enterprise-grade software tools and applications to accelerate enterprise AI research and innovation. It can be considered a purpose-built supercomputer for enterprise AI, deep learning, and machine learning workloads in a data center environment.
Looking for GPU colocation?
Deploy reliable, high-density racks quickly & remotely in our data center
Want to buy or lease GPUs?
Our partners have H200s and L40s in stock, ready for you to use today






