
As the global leader in AI hardware, NVIDIA is continuously researching and innovating GPU architecture for next-generation AI workloads. NVIDIA Hopper GPUs contain 80 billion transistors that deliver incredible performance for generative AI training and inference. Both H100 and H200 are based on Hopper architecture, but H200 offers nearly double the memory capacity and performance as compared to H100.
This article explores technical and performance differences between H100 and H200 so you can choose the best one for your workload.
Hopper architecture overview
Named after computing pioneer Grace Hopper, NVIDIA Hopper architecture introduced novel innovations for accelerating large-scale computations and complex data operations. Based on the Multi-Instance GPU (MIG) concept, it partitions a single GPU into smaller isolated instances so various workloads can run in parallel without interfering with each other. Each instance has access to more memory and compute resources for improved multi-tenancy.
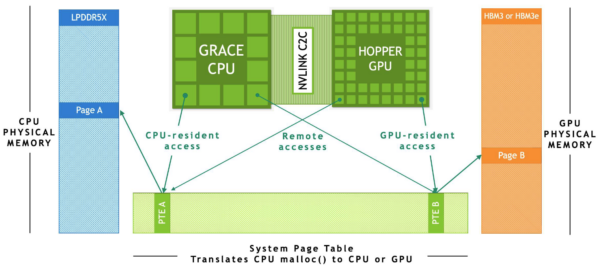
NVIDIA Grace-Hopper architecture overview (Source)
While prior architectures took a CPU vs. GPU approach to AI hardware, NVIDIA integrated the two concepts with Hopper architecture. It unified memory to reduce latency between CPU and GPU operations.
The Grace CPU and Hopper GPU each have their own physical memory for retaining data between operations. The System Page Table translates memory allocations so the CPU and GPU can access each other’s memory. The NVLink C2C, an ultra-fast interconnect, allows them to exchange data without the bottleneck of a traditional PCIe interface.
Efficient memory sharing due to NVLink and Systems Page Table allows Hopper GPU systems to process data at very high speeds.
As compared to the previous Ampere architectures, Hopper introduces the following:
Transformer engine
The transformer engine is a hardware innovation designed specifically to speed up transformer-based large language model (LLM) training and inference. All generative AI models, like GPT, Bert, Llama, etc, are transformer-based. The engine uses floating-point (FP8) precision, so AI models can perform calculations faster without losing model accuracy.
Fourth-generation tensor cores
Fourth-generation NVIDIA Tensor Cores, specialized hardware circuits, support mixed-precision calculations for AI processing. The Hopper Tensor Cores deliver up to four times the performance compared to Ampere.
High-Bandwidth Memory (HBM3)
HBM3 delivers significantly higher memory bandwidth compared to HBM2e in the Ampere architecture. Hopper can handle large-scale data and model computations while reducing bottlenecks in AI and HPC tasks.
Increased power efficiency
Hopper implements various optimizations to reduce power consumption while maximizing performance. You can reduce operational costs and run your AI workloads more sustainably.
H200 vs. H100—Architecture differences
Both H100 and H200 have the same baseline Hopper architecture and features described above. So what’s the difference between H100 and H200?
Memory and bandwidth
The key difference is that H200 HBM3e memory capacity is 1.4X times more than H100. It is the first NVIDIA GPU to offer 141 GB memory and 4.8 TB/s memory processing speed. The H200 also improves the memory subsystem for more efficient data flow between the GPU memory and processing cores. You get rapid data access for matrix operations of AI models.
NVLink
The H100 NVLink offers 600 – 900 GB/s speed, depending on mode. The H200 NVLink offers 900 GB/s speed by default, with premium models providing 2 and 4-way interconnections. This means that the H200 is better suited for scaled-out deployments where multiple GPUs are used in tandem. In large AI training workloads, where data needs to be shared across GPUs, this increase in NVLink bandwidth reduces latency and enhances performance.
Power optimization
The H200 architecture incorporates more power-efficient cores for high-intensity calculations with reduced power consumption. It has been designed to operate a 700W envelope, delivering double the efficiency of H100, irrespective of the workload you run.
Enhanced software support
The H200 offers enhanced compatibility with newer AI frameworks as compared to H100. It provides optimizations like:
- Integration with popular deep learning frameworks.
- Support for advanced AI algorithms,
- Expanded capabilities for model parallelism and distributed training.
These improvements give H200 an edge for AI training and inferencing tasks.
What is the performance of NVIDIA H200 vs H100?
S, what is the impact on performance with the changes made to H200? Independent benchmarking by NVIDIA reveals significant changes. All images in this section are taken from official NVIDIA data sheets.
LLM benchmarking
LLMs have billions of parameters—adjustable weights that define how the model processes input and generates output. LLM benchmarking evaluates how fast LLMs with 40-400 billion parameters perform tasks like image classification, natural language processing, and object detection on standardized data sets. Performance is measured for both training and inference across different NVIDIA architectures.
The H100 consistently performs 3X-4X times faster in both training and inference than the A100.
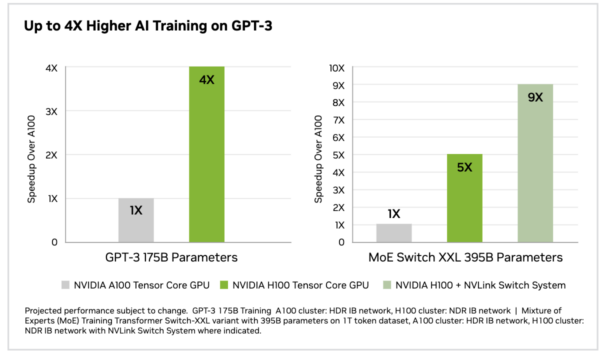
However, H200 takes this to the next level. It achieved a score of 31,712 tokens per second with the Llama 2 70B model, approximately 45% faster than the H100’s 21,806 tokens per second. Llama 2 13B and GPT-3 with 175 Billion parameters also performed 40-60% faster than H100. The performance boost is primarily due to H200’s enhanced memory bandwidth and capacity. The H200 is hands down the best GPU for AI.
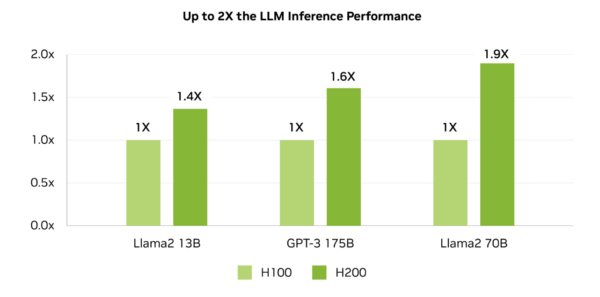
Inference performance benchmarks test AI models with standardized workloads in controlled lab-like conditions. You may not see the same performance impact in the real world. However, given the margin, you can definitely expect a 1.2 – 1.3X times performance boost irrespective of the models and deployment methods.
HPC benchmarking
High-Performance Computing (HPC) workloads are non-transformer-based and require complex mathematical operations at scale.
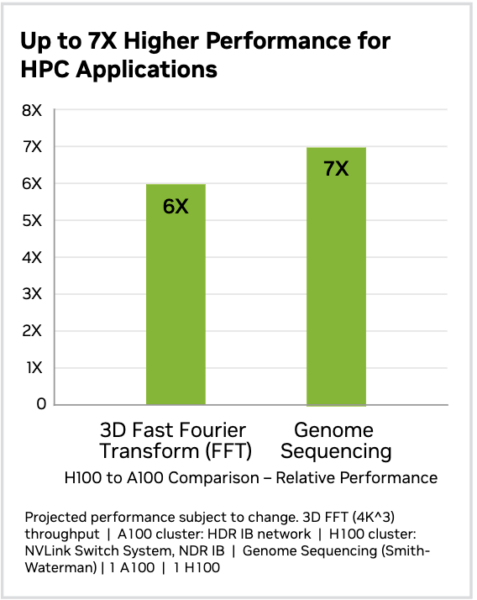
For example, The Fast Fourier Transform (FFT) decomposes complex waveforms into simpler sinusoidal components in applications like signal processing, image analysis, and scientific simulations. Similarly, genome sequencing decodes the complete DNA sequence of an organism, identifying billions of protein nucleotides that make up the genetic code. It involves analyzing massive amounts of biological data to map genetic sequences, identify mutations, and understand gene functions.
The H100 vs. A100 comparison shows that H100 gives 6x and 7x times higher performance than Ampere architecture for such applications.
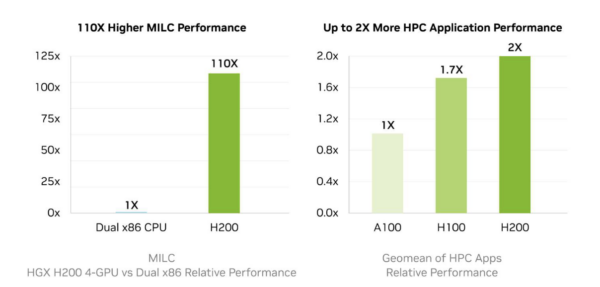
MILC (MIMD Lattice Computation) is a suite of applications used for lattice quantum chromodynamics (QCD) calculations, which simulate the interactions of subatomic particles like quarks and gluons. It involves computing large-scale matrix multiplications and solving differential equations across a lattice of points representing space-time.
The H200 achieves 110x higher MILC performance than a dual x86 CPU. Looking at H200 performance across a mix of HPC workloads, NVIDIA found that H200 provides 2x the performance of Ampere and 1.7x that of the H100. Scientific researchers can use H200 to achieve results faster and handle larger, more complex datasets.
H200 vs. H100 — Cost comparison
NVIDIA H100 pricing starts at USD $29,000 but can go up to USD $120,000 depending on your required server configurations and features. The H200 is in a similar price range, starting at just $2000 more for $31,000, but the price can go up to $175,000 and beyond depending on your server configurations.
What is the difference between H100 and H200 power consumption?
We recommend you invest in H200 GPUs as the upfront investment costs are only 10-15% higher, but ongoing operational costs can be 50% lower. If your current energy bill is $10,000/month on H100, you can expect it to drop $7000-$5000 as soon you switch to H200.
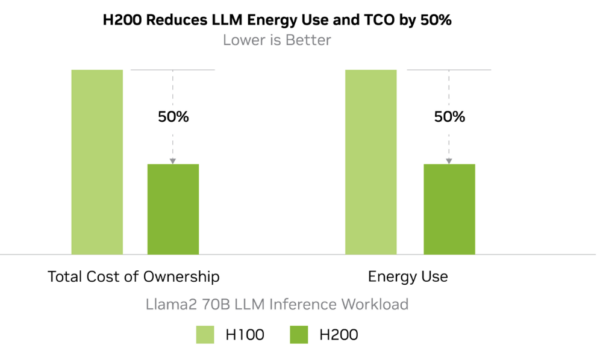
The energy optimization features of H200 allow you to recover initial investment cost differences within just a few months!
Data center vs. cloud cost comparison
Running your H100 or H200 workloads in the cloud is another option. You can avoid initial upfront investments and pay only a small amount for the workloads you run.
But is this cost-effective? Buying NVIDIA H100/H200 GPUs beats AWS rental costs within a year!
Let’s look at the pricing of AWS EC2 p5.48xlarge instances in the US(east)
|
GPU |
Price/hour |
Price/day |
Price/year |
|
H100 |
$39.33 |
$944 |
$344,530 |
|
H200 |
$43.26 |
$1040 |
$378960 |
Upfront purchase and AI colocation are much more cost-effective for round-the-clock usage, especially given the 50% drop in energy consumption of H200 hardware.
TRG data centers for H100/H200 GPU colocation
TRG data center near New Orleans can offer the GPU colocation facilities you need for NVIDIA hardware. Our facility features cutting-edge capabilities, such as waterless cooling, infinite fuel sources, and indoor generators, to provide the highest level of uptime and reliability for our clients. We provide 24/7 service and a 15-minute response time in case of emergencies. Our single-sloped roof with multiple leak-protection layers and concrete deck can protect your hardware from 185+ MPH Hurricane winds.
We use four different substations and own medium voltage infrastructure with spare parts for sustainable power supply. TRG Houston data centers have a “Critical Load” designation from CenterPoint Energy, so we get priority restoration in case of an outage.
Summary comparison of H100 and H200 specifications
|
Specification |
NVIDIA H100 |
NVIDIA H200 |
|
Architecture |
Hopper |
Improved Hopper |
|
Tensor Core Precision |
FP8, FP16, TF32, INT8 |
Enhanced FP8, FP16, TF32, INT8 |
|
Memory Type |
HBM3 |
HBM3e |
|
GPU Memory |
80GB |
141GB |
|
GPU Memory Bandwidth |
3.3-3.9 TB/s |
4.8 TB/s |
|
NVLink Bandwidth |
High |
Improved NVLink with greater speed |
|
Power Efficiency |
Optimized for AI workloads |
Further optimized (50% more reduction in consumption) |
|
Software Support |
CUDA, NVIDIA AI tools |
Enhanced compatibility with AI models |
Conclusion
Both H100 and H200 are highly optimized architectures for gen AI and HPC workloads. If you are training LLMs, deploying foundation models, running genome sequencing, or running similar HPC workloads, it is best to switch to Hopper from any other NVIDIA architecture or any CPU-based system. Switching to H100 will result in significant performance improvements. Faster workloads automatically consume less power, and power optimization in Hopper reduces power consumption even more.
However, for maximum impact, consider switching to H200. H200 is widely available cutting-edge tech in AI hardware. New AI projects must invest in H200 – the upfront cost is minimally higher than H100, and the long-term impact is significant. Not only do your workloads speed up 1.5X more—your power consumption further drops by 50%!
It is little wonder that Elon Musk set up 100,000 Nvidia H200 GPUs for X, anticipating current and future workload requirements. H200 GPUs are designed with the future of AI in mind. Investing in them is well worth it for the next decade.
FAQs
What’s better than H100?
The NVIDIA H200 is considered more advanced than the H100, offering better performance, energy efficiency, and enhanced AI capabilities. It is designed for next-gen AI, data analytics, and high-performance computing tasks.
Is H200 the same as Blackwell?
No, the H200 is based on NVIDIA Hopper architecture. Blackwell is an upgrade to Hopper and introduces AI, machine learning, and high-performance computing innovations. It delivers significant improvements over previous architectures and is considered the next milestone in AI hardware. However, at the time of writing, Blackwell is less widely available and much more expensive than H200. Read more about H200 vs. Blackwell here.
What is the NVIDIA H200 used for?
The NVIDIA H200 is primarily used for high-performance computing, AI research, deep learning, data science, and graphics rendering. Its advancements in processing power make it ideal for tasks requiring immense computational capabilities and low energy consumption.
Does H100 have ray tracing?
Yes, the NVIDIA H100 supports ray tracing, a key feature for advanced rendering tasks, though it is primarily optimized for AI and high-performance computing. Ray tracing in the H100 enhances real-time rendering quality in AI-driven applications.
How many TFLOPs is H100 vs. H200?
The H100 NVL FP16 Tensor Core offers 1671 TFLOPs, while the FP8 Tensor Core offers 3341 TFLOPs. In comparison, the H200 FP16 Tensor Core offers 1979 TFLOPs while the FP8 Tensor Core offers 3958 TFLOPs, offering improved computational power for next-gen workloads.
Looking for GPU colocation?
Deploy reliable, high-density racks quickly & remotely in our data center
Want to buy or lease GPUs?
Our partners have H200s and L40s in stock, ready for you to use today






